
Credit: Shutterstock
Oxford researchers develop tool to predict human displacement post-disaster
When disasters such as earthquakes happen, governments and humanitarian organisations need to rapidly allocate aid resources to facilitate recovery, minimise the number of people displaced and reduce the long-term effects. This is a complex task that needs be undertaken in a very short space of time, with potentially serious consequences if not done well.
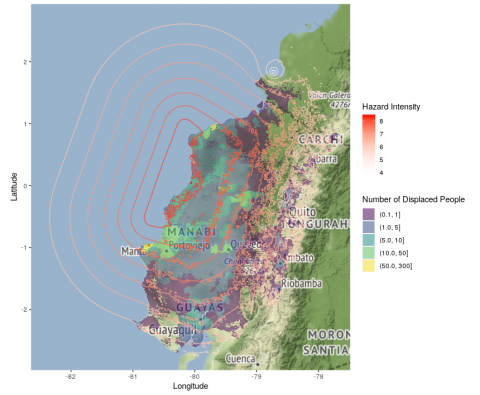
Being able to predict more accurately where people go in the wake of a disaster could be transformative for disaster management: it allows those coordinating the response to ensure shelters are placed in the best locations for the right number of people. Researchers at Department of Statistics, University of Oxford, in collaboration with the Internal Displacement Monitoring Centre (IDMC), have developed an open source software package to estimate displaced populations post-disaster, currently with a focus on earthquakes and cyclones. The software tool has been developed by Dr Hamish Patten and Prof David Steinsaltz, who form part of the department’s bio-demography group. The project, funded by the Engineering and Physical Sciences Research Council Impact Acceleration Account (EPSRC-IAA) grant, has recently been published with the Global Report on Internal Displacement (GRID) 2021.
The research involved building an open source statistical software product consisting of two components:
· a back-end system which combines the data, model and state-of-the-art statistical methods into a predictive tool, learning from a broad range of historical events in order to make well-informed and accurate predictions of displacement post-disaster.
· a front-end system that interactively visualises the data and predictions, to allow a detailed exploration of important disaster information.
In a comparison of predictions against past displacement figures for over one-hundred earthquakes in 38 different countries around the world, the tool accurately predicted the total displaced population at least ten times more accurately than world leading risk models produced by the United States Geological Survey (USGS) and the Global Disaster Alerting Coordination System (GDACS). The predictions have also enabled a mapping of how the
displaced population is expected to be spatially distributed, which can be used to identify displacement ‘hotspots’ in order to allocate resources more effectively.
By coupling the software with mobile phone data-based displacement estimates provided by organisations such as Flowminder or Facebook Data for Good, we were able to produce a detailed mapping of the returned and displaced populations over time, something that has never been done before. The choice of emergency shelter locations and capacities can also be optimised with the software: given a list of potential shelter locations and capacities, the software package will produce the optimal choice of shelters. This is based on minimising the driving time between displaced populations to each potential shelter location, whilst also considering the finite capacity of each shelter.
The tool is being integrated into the risk models for IDMC, and discussions are also underway to integrate the tool into the risk models used by the International Federation of the Red Cross (IFRC). This research could have a huge impact on aid and resource allocation post-disaster.
Dr Hamish Patten, Research Associate at the Department of Statistics, said: 'Working on predicting disaster-related displacement has been a very stimulating challenge, having to bridge between academia and industry to produce a neat and polished software product for the humanitarian sector, in only six-months. The success of the project was to recognise that many recently-emerged datasets and data sources that can be used to validate risk models have been, until now, almost entirely unused.'
About OxSciBlog
The Oxford Science Blog gives you the inside track on science at Oxford University: the projects, the people, and what's happening behind the scenes. Curated by Ruth Abrahams, Media Relations Manager (Research and Innovation).
Contact: Ruth Abrahams, [email protected]